
In our complete JavaScript SEO Guide, we will uncover the important elements of JavaScript (also known as JS) that SEOs need to know about. We’ll talk about how Google crawls and indexes JavaScript, why it benefits both users as well as SEOs and most importantly, the best practices you should follow to make your JavaScript SEO-friendly.
Whether you’re new to SEO and looking to familiarise yourself with the topic or a seasoned developer looking for a fresh perspective, this blog is just what you are looking for.
Use the links below to navigate to individual sections. And if you’re thinking of partnering with a JavaScript SEO agency, you can get a free consultation by speaking to our team today.
- What is JavaScript?
- What is JavaScript SEO?
- What is JavaScript rendering?
- Server-side rendering
- Client-side rendering
- How does Google crawl and index JavaScript?
- Other important elements of JavaScript you need to know
- What is Ajax?
- What is the Document Object Model (DOM)?
- Benefits of JavaScript for SEO and users
- How JavaScript poses a challenge for SEOs
- JavaScript can affect accessibility if not implemented correctly
- JavaScript can affect crawling and indexing
- Common issues with JavaScript SEO
- Internal linking issues
- Content accessibility for crawlers
- Content accessibility for users
- Obtainability
- Rendering issues
- Single Page Application considerations
- What happens if a JavaScript framework is deployed without taking SEO into consideration?
- Refining your approach to JavaScript SEO
- Ensure URLs are indexable and crawlable
- Don’t block JavaScript resources
- Include descriptive metadata
- Improve the page loading speed
- Provide essential content in the initial HTML response
- Add navigational elements to your initial HTML response
- Regularly test and monitor performance
- Useful JavaScript SEO tools
- URL Inspection Tool in Google Search Console
- Using your browser’s “Inspect” feature
- Mobile-Friendly Test and Lighthouse
- Page Speed Insights
- Site: Command
- Diffchecker
- Chrome DevTools
- Crawlers
- BuiltWith
- Get help with your JavaScript SEO

What is JavaScript?
JavaScript is a programming language and a core technology of the World Wide Web, along with HTML and CSS. It is commonly abbreviated as JS, hence the capitals within JavaScript.
JavaScript was first invented in 1995 by Brendan Eich while working at Netscape. Internet Explorer was the first browser to support ES1 (ECMAScript 1), the first edition of JS. JavaScript is currently on its 14th ECMAScript edition (ES14), which was released in 2023. Whilst browsers are looking to support specific features from some of these new releases, we may not see full support up to these later versions for some time to come.
The computer programming language JavaScript should not be confused with another language, Java, as they are very different. JavaScript has been noted as one of the fastest-growing languages in the world, and it’s unlikely that’s going to change anytime soon.
Modern web pages are comprised of three major components:
- HTML – Hypertext Markup Language. Imagine this to be the “skeleton” to the web page’s “physical form” – let’s use a Zebra as an example. As the bones in a Zebra skeleton provide structure, so does HTML for a site. It organises the static content on a site into headings, paragraphs, lists, etc.
- JavaScript – We have what looks like a Zebra now, but it wouldn’t be a great deal of use in the savannah as just skin and bones. JavaScript provides the “muscle” enabling movement to a form and the interactivity to a website. JavaScript is either embedded in the HTML document within script tags, predominantly in the header and footer or linked to a script hosted elsewhere.
- CSS – Cascading Style Sheets. Picture this as the “fur” that covers the ‘Zebra’ skeleton. Much like a Zebra has an instantly recognisable black-and-white appearance, the CSS is the design, style and wow factor added to a website, making up the presentation layer of the page.
Put simply, as muscles make a Zebra run, JS is a programming language that makes webpages interactive and animated, bringing a page to life to engage a user.

There is currently a wealth of JavaScript (JS) libraries and frameworks. These are essentially tools that offer pre-written code that developers can use to build websites more efficiently.
Some that we work with here at Impression include jQuery, AngularJS, ReactJS and EmberJS. As well as jQuery UI, Chart.js is a good example of the most visual. The latter is for interactive charts while the former offers a bank of user experience (UX), ‘datepicker’ inputs you see all over the web, scrollers and drag and drop. Then there is Node.js, which focuses on run-time updates, enabling pages to update in real-time.
What is JavaScript SEO?
JavaScript SEO is a facet of technical SEO that looks to improve the crawlability and indexability of websites that rely on JavaScript. Much like general SEO, the aim of JavaScript SEO is to improve search visibility and ensure that the website delivers the best experience for the user.
JavaScript SEO typically includes things such as
- Optimising content delivered by JavaScript to improve load time through techniques such as lazy loading, minification and bundling.
- Identifying and fixing JavaScript issues
- Following internal linking and mobile SEO best practices
What is JavaScript rendering?
Rendering focuses on fetching the relevant data to populate a page, and the visual layout templates and components and then merging them to produce HTML that a web browser can display.
It’s here where we should introduce two fundamental concepts: server-side rendering and client-side rendering. Every SEO managing a JavaScript website must recognise the difference between the two.
Server-side rendering
Server-side rendering (SSR) is when the webpage is generated on the server and then sent to the browser fully rendered. This involves a browser or a search engine bot (crawler) receiving HTML markup that describes the page exactly.
Once the content is already in place, your browser or the search engine bot must download the attached assets (CSS, images, etc) to present how the page has been designed. As this is the traditional approach, browsers and bots do not generally have a problem with SSR content.
Websites that use SSR are typically programmed in PHP, ASP or Ruby and might have used popular content management systems like Kentico, WordPress or Magento.
Client-side rendering
Client-side rendering (CSR) is the opposite of server-side rendering (SSR). In CSR, JavaScript is executed in the user’s browser or by the search engine bot rather than on the server. This means the browser first loads a basic HTML page and then uses JavaScript to build and display the content dynamically.
Many search engine bots have been noted to struggle with CSR because, initially, they will see a blank HTML page with very little content. This makes it harder for search engines to immediately understand and index the fully-rendered content as it isn’t visible right away.
Luke Davis, senior technical SEO specialist at Impression, advises the following when choosing the appropriate rendering solution for your site:
“It’s so important to pick the right rendering solution for your site. You have to carefully balance resources, server costs, and general maintenance and make sure that the content you need users to see is also visible to search engines. That’s why server-side rendering is usually the default solution for many sites: it’s popular, relatively easy to manage, and serves content in a way that works for users and bots.”
A common workaround suggested by Google in the past was dynamic rendering. This approach offers server-side rendering to bots that can’t render JS-generated content but still serve client-side rendered content to users. While that offers a happy medium, this kind of rendering solution comes with its own problems and resource requirements, making it more of a short-term fix.
Google now recommends using server-side rendering, static rendering, or hydration as a solution. Static rendering is similar to SSR, but it is triggered at build time (when the website is deployed or updated) rather than at request time. Hydration then takes place after the static content is rendered and delivered to the browser to serve dynamic content and interactivity.
If you need more advice on choosing the best rendering solution for your website, we can help. Head over to our JavaScript SEO services page to learn more about the support we offer to help improve how search engines crawl, index, and rank your JavaScript-based content.
How does Google crawl and index JavaScript?
Google crawls a website using its ‘Googlebot’ crawler and indexes with the ‘Caffeine’ infrastructure. Each performs very different functions – Googlebot is all about discovery.
Googlebot essentially processes JavaScript in three major stages these being;
- Crawling
- Rendering
- Indexing
As shown in the diagram below, Googlebot places pages within a queue for their crawling and rendering processes. From here, Googlebot fetches a URL from the crawling queue and reads the robots.txt file to see whether the URL has been disallowed or not.
From here, Googlebot then parses the HTML response to another URL and adds it to the crawling queue. Once Googlebot’s resources allow, a headless Chromium renders the page and executes the JavaScript. This rendered HTML is then used to index the page. We’ll take a closer look at what JavaScript rendering is in the next section.
However, during Google’s 2018 I/O conference, they stated that JavaScript is now being processed in two separate waves. These waves can take a couple of days – a week to properly index JavaScript-heavy websites, but Google is actively working towards rendering in near-real-time. The diagram below displays the process Googlebot goes through when indexing.
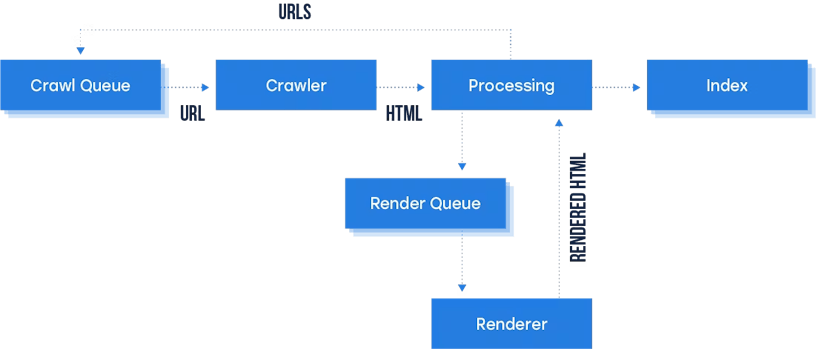
JavaScript rendering process: Crawl queue to the crawler. During the processing, the URL is queued to render; once rendered, it indexes the URL.
As Google is running two separate waves of indexing, it is possible for some details to be missed during the indexing process. For example, if you’re not server-side rendering crucial title tags and meta descriptions, Google may miss this on the second way, having negative implications on your organic visibility on the SERPs.
Other important elements of JavaScript you need to know
What is Ajax?
Asynchronous JavaScript and XML, known as AJAX, is a set of web development techniques combining, you guessed it, JavaScript and XML to create asynchronous web applications.
Asynchronous means “not existing or occurring at the same time”, so the web applications can communicate with a server without interfering with other functions or lines of code on a page by operating in the background.
Usually, all the assets on a page are requested and fetched from the server and then rendered on the page. AJAX can be implemented to update the content or a layout without initiating a full page refresh. Usefully, as often, pages on a site don’t differ greatly, using AJAX means only the assets that differ need to be loaded, which improves the UX.
A great example of this in action is Google Maps; the page updates as the user navigates without a full page reload.
What is the Document Object Model (DOM)?
Think of the Document Object Model (DOM) as the web browser’s actions taken after receiving the HTML document to render the page.
It is essentially an application programming interface (API) for markup and structured data such as HTML and XML.
The HTML document is the first thing the browser receives. Following that, it will start analysing the content within and fetching additional resources, such as images, CSS, and JavaScript files. What forms from this parsing of information and resources is referred to as the DOM. It can therefore be thought of as an organised, structured interpretation of the webpage’s code. A “bridge” that connects web pages and programming languages.
While the DOM is a language-agnostic (unrestricted to a specific programming language or library) API, it is most commonly used in web applications for JavaScript and dynamic HTML.
As a result of dynamic HTML, the DOM is often very different from the initial HTML document.
Dynamic HTML is the ability for a page to change its content depending on user input, environment (such as time of day), and other variables, leveraging HTML, CSS, and JavaScript.
From an SEO perspective, it’s important to understand the DOM because it’s how Google analyses and understands webpages. Visually, the DOM is what you see when you “Inspect Element” in a browser.
Benefits of JavaScript for SEO and users
JavaScript is being used more and more across the web to provide more dynamic experiences to web users. This trend has been growing in recent years, with websites like Airbnb running solely on JavaScript (in this case, a variant of JavaScript called React JS).
JavaScript allows you to add dynamic elements to web pages, which can enhance interactivity, making it more engaging for the user. Other features like infinite scroll and interactive maps, which are delivered through JS, also help to improve the user experience.
While the experiences produced by JavaScript can be really good for users, the same cannot always be said for Google and other search bots. This is because they can struggle to render JS unless managed correctly. The reality is that websites seeking to use JavaScript must consider Google in their implementation, ensuring their site can be crawled, rendered and indexed effectively. Google certainly wants to provide users with the best experience, and so there is a gap to bridge here.
JavaScript is a very useful tool when utilised correctly, but it is by no means perfect. As with everything, it’s about picking the right tool for the job. Developers may prefer to work with a language they’re very familiar with rather than creating something in another language that could perform better. If you’re working with a developer and you are unsure of whether they are using the right tool for the job, the best approach is to always ask questions with an open mind.
Let’s look at some further considerations and challenges.
How JavaScript poses a challenge for SEOs
Unfortunately, many JavaScript frameworks are deployed without SEO considerations taken into account, which can have a drastic impact on the overall performance of the website.
JavaScript can affect accessibility if not implemented correctly
As long as there isn’t a script that is device-dependent (requires a mouse or keyboard), then a web page containing JavaScript will normally be fully accessible. JavaScript has the potential to optimise the visitor experience and improve accessibility, but it’s all based on how it’s used.
When JavaScript has been utilised to create visual interface elements, such as an image change when hovering over with a mouse cursor, this interaction typically requires a mouse or another interaction device like a laptop touchpad or drawing tablet. As a result, this type of interaction may not be considered fully accessible. However, if this does not affect the important content being displayed on the page, then it does not necessarily need to be addressed.
For SEO, the user is the focus, and we want to ensure that everyone can access and view a page. The user should be able to see the same important content regardless of whether they have JS enabled or not.
JavaScript can affect crawling and indexing
As previously mentioned, the main issue with JS is that if bots are unable to find URLs and understand the site’s architecture. This can cause crawling and indexing to become slow and inefficient.
On JavaScript-based websites where internal links are not part of the HTML source code, crawlers initially discover only a limited set of URLs. The crawler then has to wait for the indexer to render these pages before extracting new URLs, causing multiple revaluations of the internal site structure, which can cause the relative importance of pages to change. This can lead to key pages being overlooked or deemed unimportant, while less important pages might appear to have higher value due to their internal links.
Internal linking is a key signal for search engines to understand a site’s architecture and page importance. If internal links are missing from the HTML source, Google may spend more time crawling and rendering the wrong pages over the pages you actually want to rank.
As a resolution, internal linking should be implemented with regular anchor tags within the HTML or the DOM rather than using JavaScript functions to allow the user to traverse the site.JavaScript’s onclick events are not a suitable replacement for internal linking. While certain URLs might be found and crawled, likely through XML sitemaps or in JavaScript code, they won’t be associated with the overall navigation of the site.
Another issue to avoid is blocking search engines from your JavaScript. If this happens, search engines will not be able to see the most important content on your site, which can negatively affect your SEO efforts.
The best way this can be resolved is by working with your website development team to determine which files should and should not be accessible to search engines.
One recommendation is to implement pushState, which is navigation-based and used to manipulate the browser History API. Simply, pushState updates the address bar URL, ensuring only what needs to change on the page is updated.
The best use of pushState is seen with infinite scroll (when the user scrolls to new parts of the page, the URL will update). This means the user shouldn’t need to refresh the page, as the content updates as they scroll down, while the URL is updated in the address bar.
Common issues with JavaScript SEO
Internal linking issues
Internal linking is considered a strong signal to search engines regarding the complete website architecture and the overall importance of pages. JavaScript-based internal linking might not be recognised by search engines if they are not included as part of the static HTML.
If internal links are being provided via JavaScript, the rendering process needs to occur before the crawler is told where new links are on the site to crawl. This can result in a back-and-forth between the rendering process and the Googlebot crawler, slowing down both the crawling and indexing processes.
With internal linking being one of the webmaster’s top priorities, regular anchor tags should be used within the HTML or the DOM as opposed to leveraging JavaScript functions. such as JavaScript onclick events to allow the users to traverse from web page to page across the site.
Content accessibility for crawlers
For content to be clear for both the user and search engine bots, the content must be indexable within the load event, require an indexable URL and use the same best practices SEO for HTML applied to render JavaScript sites. Not only this, but as aligned with basic SEO practices, each piece of content on a website should be unique, from the website itself and across other sources on the internet, shouldn’t be duplicated.
Content accessibility for users
If the JavaScript hasn’t been coded with accessibility in mind, this can make it hard for users who rely on screen readers and other assistive devices to access the content. If your website relies on mouse or specific keyboard actions to view important content, this can create a barrier for users.
Search engines will prioritise websites that are accessible to a broader audience. If your website doesn’t provide an accessible experience, it can lead to lower engagement and a higher bounce rate, which will reduce your chances of ranking well in the search results.
Furthermore, if all the HTML and content are loaded in after the initial server response (client-side rendering), then it can potentially result in the rendering process not detecting any content on the page if the rendering process test finishes before the content has loaded in.
When content isn’t rendered, you are serving less content to a search engine than a user, and this can further impact your organic ranking performance.
Obtainability
A number of search engines will deploy headless browsing, a type of software that can access web pages, but does not show the user and transfers the content of the web page to another program that runs on the backend. A headless browser helps to render the DOM to gain a better understanding of the user’s experience and the content situations on the page.
However, it’s important to understand how JavaScript is executed and interacted with by search engine bots, with huge organic consequences if not. An example of this is the globally renowned brand Hulu, where a significant visibility drop was seen due to a coding problem and the way the site was serving JavaScript to Googlebot. For further information on this drop-off in traffic, read the Hulu.com JavaScript Fail case study.
Rendering issues
JavaScript can affect the overall rendering of a web page. Therefore, if something is render-blocking, this is likely to delay the page from loading as quickly as it has the potential to. As a rule of thumb, Google recommends completely removing or at least deferring any JavaScript that interferes with the loading of “above the fold” content on a website.
Above the fold refers to the part of the web page that is visible when the page initially loads. The subsequent portion of the page that requires scrolling is called “below the fold”. This can be apparent across a range of devices, including desktops, mobiles, iPads and many more.
Single Page Application considerations
A single-page application (SPA) is a web application or website that has been primarily designed and built to operate efficiently on the web. These pages are dynamically rewritten and loaded with the pieces you require, as opposed to loading an entire page from the server.
The SPA approach provides a fast loading time, uses less bandwidth and provides the user with a pleasant experience by making the application behave more like a desktop application. It should be noted that there are many different SPA framework options available, depending on the use of the application. These include React.js, Angular.js, Backbone.js, Preact, Next.js and hundreds more.
When rendering SPAs, John Mueller, Search Advocate at Google, stated the following:
“There can be many hurdles when Google attempts to crawl and index the content on the SPA. Therefore, if you’re using SPAs, it’s recommended to test out multiple times, using the Fetch command, to understand what Google is able to pick up.”
What happens if a JavaScript framework is deployed without taking SEO into consideration?
If a JavaScript framework is deployed without considering SEO, then the worst-case scenario is that search engines, like Google, may not be able to read the content on the website.
Without access to the content, Google may view the pages as lacking relevant content, making them irrelevant to specific search queries. If left unresolved, the website may be de-indexed, causing it to disappear from the search results.
This sounds scary on its own, but if the majority of your business comes in digitally, then this sort of issue will result in a drastic drop in business and conversions until it is resolved. This can also have an impact on paid advertisements. If the page’s content can’t be seen by the search engines, then it could also prevent any paid advertisements via a search engine from being shown. The search engine will see it as having no relevance to your target keyword and instead will prioritise other advertisers that do have relevance.
Any advertisements like dynamic search ads (DSA) campaigns that utilise content from the page for the advertisement won’t display due to finding no content.
This scenario highlights the importance of JavaScript frameworks working well from both a user and SEO perspective. Poor usability can negatively impact rankings, and JavaScript that causes significant delays in page load times or hides crucial content can also harm SEO.
Seeking advice from an experienced JavaScript SEO agency can help you avoid these common pitfalls when looking to use JavaScript-based content on your website. Below, we’ll explore some of the best practices and tools you can use to follow for implementing a successful JavaScript SEO strategy.
Refining your approach to JavaScript SEO
Ensure URLs are indexable and crawlable
To ensure that JavaScript-based URLs are indexable by search engines, it’s crucial to follow best practices that enhance crawlability and SEO performance. URLs should be clean and static whenever possible, and you should avoid using hashbang URLs and query parameters as these can confuse crawlers.
To ensure that content is rendered and sent to the search engines as fully indexed HTML, you should look to implement server-side rendering where possible, as this will prevent reliance on JavaScript execution.
Don’t block JavaScript resources
Often, websites will block resources they think have no importance to a search engine or a user. If your page is feeding content into a page via JavaScript, ensure the JavaScript resources that do this are crawlable and aren’t being blocked in robots.txt.
Include descriptive metadata
With each individual page on the site having a specific focus and target, they should also include descriptive titles and meta descriptions to help search engine bots and users precisely detect what the page is about. Not only this, but it also helps users determine if this is the most suitable page for their search query.
Improve the page loading speed
Google indicated that page speed is one of the signals used by their complex algorithm to rank pages, as well as a faster page speed allows search engine bots to increase the number of pages, helping with the overall indexation of a site.
From a JavaScript point of view, making the web page more interactive and dynamic for users can come with some costs with page speed. To mitigate this, lazy loading can be advised to use for certain components, usually ones that aren’t fully required above the fold.
Provide essential content in the initial HTML response
Search engines rely on the initial HTML to crawl and index the content. By including essential content such as title tags and meta descriptions in the initial HTML, it will allow the search engines to crawl the content directly.
If important content is hidden behind JavaScript, search engines may not index it properly or at all, hurting the page’s visibility in search results.
Add navigational elements to your initial HTML response
You should ensure that navigational elements, like links, menus and pagination are all included in the initial HTML response of the webpage rather than relying on JavaScript to load them dynamically after the page has been rendered.
You should also include regular anchor tags (<a href=”…”>) as opposed to the onclick attribute for your links. This is because search engines can’t trigger JavaScript events to load additional content, therefore, any pages or content behind these navigational links could be missed.
Regularly test and monitor performance
To ensure that JavaScript is running effectively and not negatively impacting the overall performance of your website, it’s essential to test and monitor it for both desktop and mobile devices.
Testing should cover various aspects, such as measuring page speed, Core Web Vitals, and crawlability. This will help you pinpoint areas where JavaScript or other elements might be causing delays or issues.
To test whether your website is optimised for both search engines and users, you can use a variety of tools and techniques. We’ll cover these in the next section.
Useful JavaScript SEO tools
With the endless capabilities JavaScript has, there’s an abundance of helpful tools available to assess and fix issues with JavaScript code. Here are just a few that we find helpful as an SEO agency.
URL Inspection Tool in Google Search Console
Found within Google Search Console, the URL Inspection Tool allows you to analyse a specific URL on your website to understand the full status of how Google is viewing it.
The URL inspection tool provides valuable data about crawling and indexing and highlights whether any errors are occurring and why. It also provides further information from Google’s index, such as details about structured data, along with any errors.
Using your browser’s “Inspect” feature
To review rendered HTML and general JavaScript elements, the Inspect Element of Google Chrome can be used to assist users in discovering further information about the webpage that is hidden from the user’s view.
To discover hidden JavaScript files, such as user behaviour when interacting with a web page, you can attain this information from the Sources tab of the Inspect Element. If you loaded the desired page before opening the Sources tab, then you may need to perform a refresh whilst the Sources tab is open to see the full list of sources for that page.
Inspect is the more comprehensive method to view JavaScript-led sites, as it will show you what’s on the page currently, so if anything is dynamically loaded in after the initial page’s response (server response), then it can be seen within inspect – this is known as client-side rendering. Server-side rendering will look to send the HTML with the initial server response and is more search engine friendly.
You can test whether your website uses client-side rendering by going to view-source and comparing it against inspect. If all HTML and content can be found in both view-source and inspect, then the website is utilising server-side rendering. If you can’t find any of the content of the pages within view-source, then it is utilising client-side rendering.
There is the potential that it may be a mix as well, where important HTML and content are being sent via server-side rendering, but a more dynamic section of the page is being delivered via client-side rendering. You can utilise Diffchecker for a more comprehensive view of what is different between view-source and Inspect.
An example of this can be seen on YouTube, where we have a screenshot of a video on the website’s homepage that looks to deliver personal recommendations based on your viewing history:
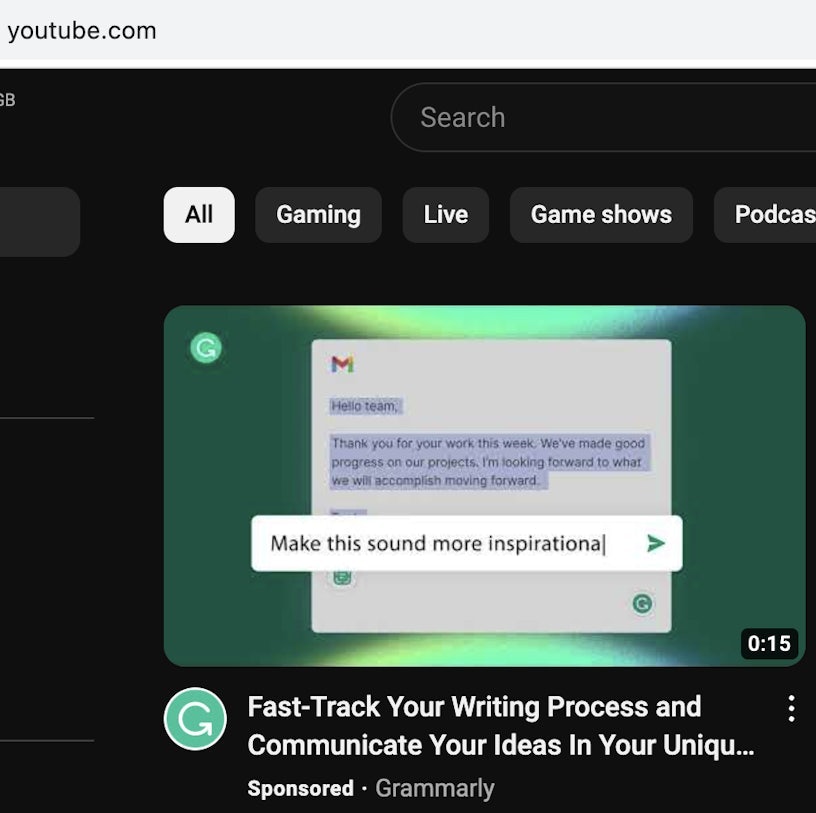
But when we looked at the source code and ran a search for “your writing process”, it didn’t find anything:
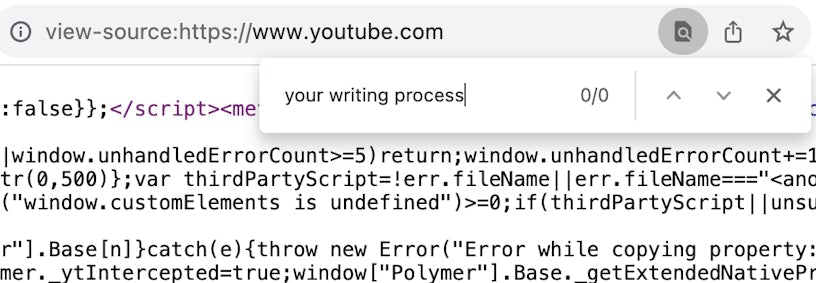
But should we then run this same search on Inspect, we can see the video title, which indicates that the website uses client-side rendering and that this content is dynamically loaded in after the initial page load:

Mobile-Friendly Test and Lighthouse
For a more detailed description of any mobile-friendly issues or recommendations for the page, you can utilise the Lighthouse test found in Google Chrome’s DevTools. This can be accessed by opening the Inspect tool and navigating to the Lighthouse tab. Once a test has been completed, navigate down to the mobile-friendly section, and you will see an overall score out of 100. It will also provide you with recommendations to improve mobile friendliness.
Page Speed Insights
Google’s Page Speed Insights tool (PSI) effectively details the mobile and desktop performance of a page. In addition to this, this tool also provides recommendations on how this can be improved.
If you are going down this list and have tried out Lighthouse, you will notice that PSI and Lighthouse are similar, this is because PSI utilises Lighthouse for its test.
Lighthouse is more commonly used by developers as it provides in-depth recommendations and analyses of the page you’re currently on, whilst PSI will fetch the page and test it. This means that if you have a page in staging/testing that is not yet live and behind a login, then PSI will likely be unable to test the page whilst Lighthouse can, provided the user is past the login stage.
Page Speed Insights also provides CWV data on how the page has performed on average with users, if there are enough visits and data available from user experiences to provide this information.
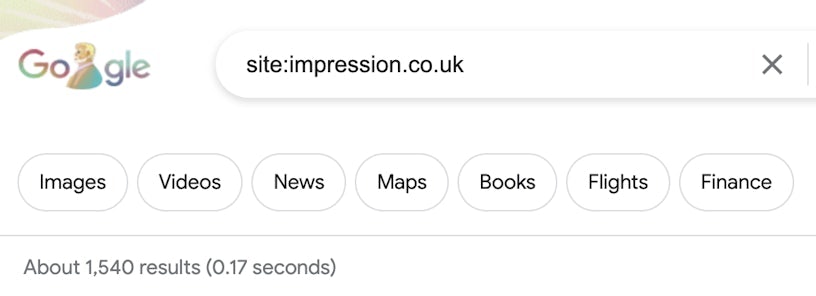
Site: Command
The site: command is one of the most direct tools to help see if Google has properly indexed your content. In order to do this, you can complete the following command in a Google search:
site: https://www.example.com “text snippet or query”
Replace “https://www.example.com” with your website or a specific category/page if you want to see pages that contain that category or a specific page only.
The text snippet or query is optional; if you don’t know the URL of a specific page you want to test, but know its overall topic/focus, you can enter a strong relevance keyword for that page for it to find the most relevant results found on your site for said keyword.
The two can be used in combination, so you know the page is within a specific category and you don’t know the URL off by heart, but you know it’s about a specific topic, then:
site: https://www.example.com/category/ “specific topic”
If no “text snippet or query” is added to the site command and you enter the root domain URL (often the homepage) then the Google search result will provide a rough count of how many pages on the site are indexed on the search engine.
Diffchecker
Diffchecker is a unique tool that allows you to compare two types of text files and review the differences between them. This is especially useful for performing an analysis of a webpage’s original source code against the rendered code. This tool delivers comprehensive comparisons of how the content has changed after being rendered.
Chrome DevTools
Chrome DevTools is a set of tools for experienced web developers to build directly into Google’s Chrome browser. Chrome DevTools can help you edit and make quick styled changes without needing to use a text editor. It helps to discover problems in a fast manner, which in turn, can help to build better websites in a quicker period.
You can access this via Inspect, which we talked about earlier, or via the 3-dot menu > More Tools > Developer Tools
Crawlers
There are a myriad of crawlers available on the market that can crawl as a JavaScript crawler or imitate Google’s crawler and rendering process. We have listed a couple of our favourites below:
Screaming Frog: A crawler that is constantly updated with new features, has lots of helpful usage guides on their site, allows for custom extraction of specific elements on the site and is used by a very large percentage of SEOs within the industry.
SiteBulb: A crawler that is growing in popularity and provides easy-to-understand ‘hints’ which are recommendations on areas of improvement for the site’s SEO/visibility on search engines.
BuiltWith
BuiltWith is a free website profiler that helps to discover what framework websites are built with. Not only this, but it’ll also tell you about any integrations with a third-party website that the website has.
Get help with your JavaScript SEO
If you’d like to find out more information regarding JavaScript SEO or you’re undergoing some crawling or indexation issues due to JavaScript code, contact our team to learn more about our JavaScript SEO services.

