
The robots.txt file is a core tool in any technical SEO specialist’s arsenal. Auditing it is paramount in any standard technical SEO review due to the hard-line nature that typically comes with the file.
Unlike other SEO components, directives within the file are usually more respected (for search engines, anyway) as opposed to just being hints or general suggestions. Configuring them incorrectly, therefore, can prove harmful to your site’s organic visibility.
What is a robots.txt file?
Found at root domain level, i.e. /robots.txt, the robots.txt file is an exclusion protocol targeted at web crawlers. It’s designed to communicate which parts of a site they are allowed and, more commonly, not allowed to crawl. This is done by setting crawl directives.
Crawl directives are signified by the Disallow: or Allow: syntax whereby you state which URLs on your site are permitted for crawling. Crawl directives then need to be coupled with a user agent target, i.e. User-agent:, in order to form the “rules” for web crawlers to abide by.
Here’s an example of a robots.txt rule that’s typically found on a WordPress site;
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Here, all user-agents are targeted, as signified by the asterisk symbol. Two directives then follow; the first stating to not crawl /wp/wp-admin/ with the second stating to override the first disallow directive, but only for the following URL; /wp/wp-admin/admin-ajax.php.
At its core, its purpose and setup is relatively straightforward. However, I still witness some misconceptions regarding the robots.txt file where SEOs still overlook it’s impact on the remainder of a site’s organic presence. I’d like to unpack these here.
Here are to some things to remember before opting to disallow URLs and directories via robots.txt.
What is a robots.txt file’s purpose?
Robots.txt is concerned with crawling – no more, no less.
However, depending on where you look, it’s still used interchangeably with the notion of indexing. Here’s a screenshot from Ryte.com’s Website Success tool where they knowingly muddle the differentiation.
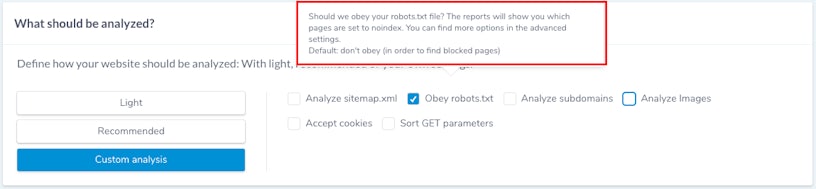
When setting a crawl, Ryte asks the user whether they want their crawler to obey the robots.txt or not, in order to find “which pages are set to noindex”.
This is incorrect.
A page disallowed by robots.txt can still find its way into a search engine index. The notion of “noindex” (alluding to the use of the meta robots noindex tag) becomes applicable after a crawl and determines whether or not to include an item of content into a search engine’s index.
Google explains this clearly in their guidance below;

This is where understanding the definition of crawling and indexing is essential, especially when applying the two to robots.txt files.
Crawling is the process search engines take to navigate around the web to find information – this is where robots.txt becomes applicable.
Indexing, on the other hand, is the process after this, where new or updated information is stored, processed and interpreted – this is where the notion of a meta robots noindex tag would apply.
Granted, my point here is simply regarding nomenclature. You may well be aware of the differentiation between crawling and indexing and the tools you can use to control these two constructs. However, to those less versed in the nuances of technical SEO, it’s a fundamental requirement to ensure you understand how search works.
What’s more, if these definitions are not understood, you can run into problems when it comes to applying robots.txt into your SEO strategies.
How it can impact your index presence
While the robots.txt file is there to manage crawl traffic, a consideration still needs to be made on the impact it can have on your site’s index presence.
We know that a disallowed page can still find its way into the index – this has been confirmed and documented by Google several times. When this happens, snippets like this find themselves in SERPs;
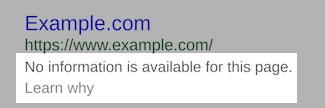
But what causes this? Likely three things, either;
- The page is being linked-to via an external source, or;
- The page was already crawled and indexed, with the disallow directive being applied after;
- The directive that the page applies to has been ignored (this is increasingly uncommon, though it’s still accepted that it can happen).
So when Google attempts to index the page again, the content is largely unavailable (aside from a few components). Finding exactly where this occurring on your site is now made simple via the new Search Console by navigating to Coverage > Valid with warnings > Indexed, though blocked via robots.txt.
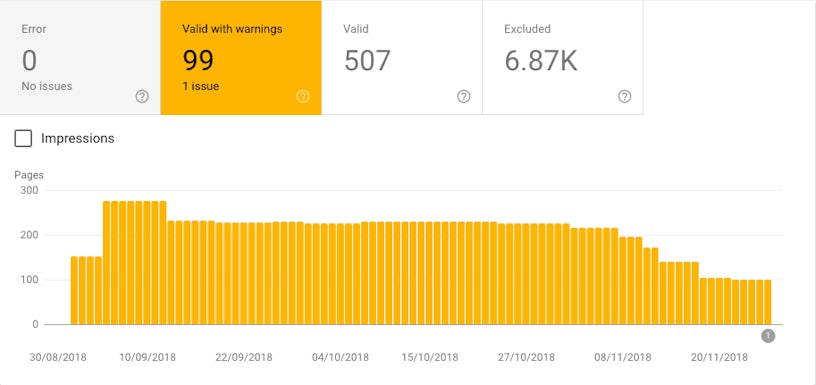
Here, you’re able to pinpoint exactly which URLs are being blocked by your robots.txt file but still discoverable via search.
Now, it’s short-sighted to instantly presume these are critical errors. Google themselves class them as warnings, acknowledging how they may be intentionally set like that. If it is a necessary evil then so be it. However, if it was unintentional, then some further investigation is worthwhile by looking at each blocked but indexed URL individually.
What you need to decipher is why these URLs were disallowed in the first place. If it was to reduce duplication, then a far more optimal solution is to consider canonicalisation. If the intention was to remove the page from search entirely then a meta robots noindex tag is more appropriate. Finally, and arguably most importantly, if a URL has been blocked by mistake then this needs to be resolved altogether by removing the disallow.
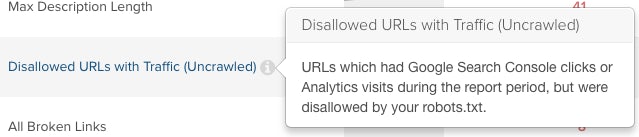
Making blanket recommendations in technical SEO is difficult since the discipline is so dependent on context. However, what remains true is keeping an eye on these URLs. After all, having several blocked URLs indexed can dilute your index presence and make for a sub-optimal search experience. This is especially the case if disallowed URLs are still receiving organic traffic, which can be identified via DeepCrawl and their “Disallowed Pages with Traffic” report.
How it impacts link equity
Another point to consider before disallowing via robots.txt is how it prevents the spread of link equity. This is important to bear in mind if you’re looking to introduce robots.txt directives as a means to control crawl efficiency.
Again, it’s not a one size fits all solution as managing crawl budget typically comes with some trade-offs depending on the avenue you go with. Luke Carthy conveyed this perfectly during his talk at SearchLeeds 2018, “How to Optimise the S*** out of Your Internal Search”. It’s the below slide in particular that outlines your options well;
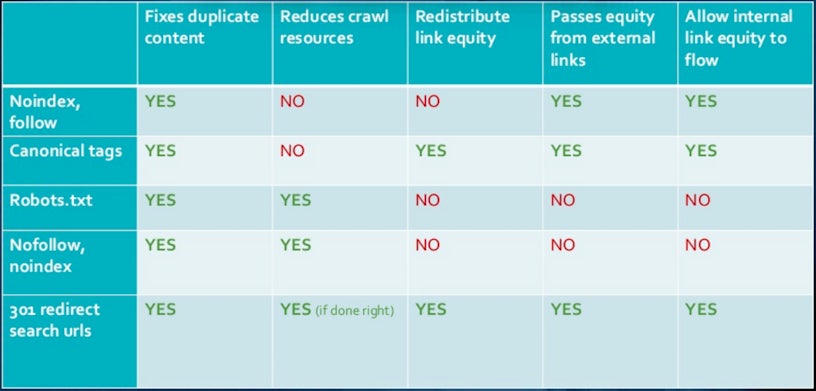
As we can see, while disallow directives via robots.txt “fix” duplicate content issues and improve crawl efficiency, the setup comes with negatives implications your regarding internal and inbound links.
It’s the inbound links we need to be particularly concerned with, especially if they’re of quality. Ensuring these link to URLs that are able to redistribute link equity is the main objective here to ensure your site benefits from the authority. DeepCrawl can visualise this for you with their “Disallowed URLs with Backlinks” report.
Working directly with DeepCrawl’s Majestic integration, this report allows you to investigate all links with disallow directives applied to them. From there, it’s a case determining a resolution such as removing the disallow, redirecting the URL to a more appropriate destination or even asking the site owner to reposition the link to a landing page that’s more integral to your SEO strategy.
Rounding up robots.txt
Robots.txt is a powerful tool that needs to be handled carefully. Typically, you’re safe to use the file to avoid user agents crawling unimportant content but even then, the definition of “unimportant” becomes inherently problematic!
Above all, it’s important to remember the implications it can have on your index presence and link equity. Always consider all the options available to you, such as canonicalisation, meta robots tagging or even authentication if the content you’re looking to deter search engines from is particularly sensitive or private.
If you have any further thoughts about this post or when you think it’s best to use robots.txt, feel free to let me know on twitter.

