
What is Google’s Natural Language API?
Google’s Natural Language API uses machine learning, a type of artificial intelligence, to reveal the structure and relationships within a text. The tool identifies the entities (things) within the text, gives these a salience (importance) score and also determines the sentiment (feeling) of the text. They have released a free demo for users to experiment with and better understand the metrics.
Google has always worked on improving the relevance and quality of the search results for the user. By using natural language processing (NLP), Google can better understand the topic of the text and the importance of the entities within, thereby determining important ranking signals such as Expertise, Authoritativeness and Trustworthiness (EAT).
What is an Entity?
Entities are things within the text, which are identified by the API and separated into categories, such as Person, Organisation, Location etc. Each entity is also given an entity salience score – the level of importance within the text.
The NLP tool can recognise where a person or an organisation is mentioned in different ways, but still recognise that it’s the same entity. For example, a job title and a person’s name could be seen as the same entity if they are only used together within the text, such as “President” and “Barack Obama” becoming one entity – “President Barack Obama”.
Entities are also given a magnitude score. This score can help you to understand the level of emotional content within the text. Google explains that you can distinguish truly neutral articles or documents, as they will have a low magnitude score. However, mixed documents containing differing or contrasting opinions will have higher magnitude scores.
What is Salience?
Salience refers to the importance of an entity, with the score based upon its relative prominence within the text. Google attempts to predict both salience and sentiment scores as close to human perception as possible.
The lower the score, the lower the importance of the entity in that particular text. The scale is between 0 and 1 – if an entity is closer to 0, it is deemed less important within the overall text.
The most salient phrase could only be mentioned once or twice, but depending on how it is mentioned, it could make it the most important in the text. The grammatical function of the word determines the prominence of an entity within the text. You can read more about this in Ben’s Entity Salience blog.
What is Sentiment?
Sentiment is the overall feeling of a text, and the sentiment score is based upon the overall positivity or negativity of the text. For example, an article about a sports team winning a game is likely to have a positive sentiment score, whereas an article about a criminal being arrested is more likely to have a negative sentiment score.
The idea of measurable sentiment piqued my interest as something that could provide valuable insights for our clients. For example, I wanted to understand whether Google’s sentiment analysis could be used to understand the sentiment of coverage achieved by our Digital PR team, meaning that we could potentially provide an additional reporting metric around the quality of coverage.
I set up the following experiment to test our hypothesis, which was that Google’s Natural Language Processing tool is a viable measurement of sentiment for digital marketers.
Testing the Natural Language Processing API
In order to test the sentiment analysis, I ran ten articles about a local Nottingham business through the tool – five positive and five negative. Of course, these perceptions were my own, and so there is the potential for human bias within my results (which I will discuss further later on).
The positive articles were expected to receive a high sentiment score and the negative articles to receive a low sentiment score.

The whole article was given a sentiment score, followed by entity-level sentiment. I recorded the score of the entire article, as well as the score of the company name as an entity.
I will be referring to the articles as Positive Article 1, Positive Article 2 etc., to respect the privacy of the company.
Research Findings
Positive Sentiment
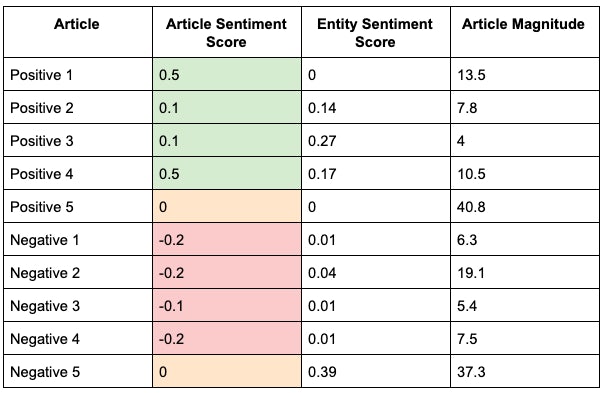
- Of the five articles that we classified as “positive”, four received a positive sentiment score from Google’s tool.
- One of these was an article about a charity donation, which seemed inherently positive.
- The other three articles were about new business and plans for the future.
- The fifth article received a “neutral” score.
Negative Sentiment
- Out of the five articles we classified as “negative”, four received a negative sentiment score from Google.
- All of these negative scores were given to articles surrounding money and funding.
- The article which received a neutral score was surrounding politics – perhaps it was my own bias that made me categorise it as a negative article.
Neutral Sentiment
- Two of the articles received a neutral sentiment score from Google.
- Of these, I classified one as “positive” and the other “negative”.
Google has explained the neutral scores:
“A document with a neutral score (around 0.0) may indicate a low-emotion document, or may indicate mixed emotions, with both high positive and negative values which cancel each other out.”
As I discussed before, articles with mixed opinions will also have a higher magnitude score (the volume of differing emotions). This is clear to see from the results, as both of the neutral articles had the highest magnitude of all the articles, showing that there was a conflict of opinion within the text.
Results
The results of the research show that 8 times out of 10, Google’s NLP tool agreed with my own classification of sentiment. For a relatively new tool, this is not bad. It would be interesting to find out how they trained the sentiment analysis model, but in true Google style, they have not released any information about the detailed structure.
We discovered that articles containing conflicting opinions can produce a neutral result from the tool. However, there is another factor I have mentioned which could have affected the results – bias.
How does the tool determine whether an entity is positive or negative? Well, it is given training data to learn from, via the human technicians.
Training Data & Potential Bias
Human bias is a prominent issue when it comes to artificial intelligence. For example, when choosing whether an article was positive or negative, I used my own opinions to decide. When the journalist was writing the article, they used their own opinions within, whether it was conscious or unconscious bias. In the same way, the labelling process for training data has to start with humans.
Sentiment analysis will only be as good as the training data that the API has been given.
Inevitably, there is human bias within the training data that was selected for the Natural Language API, via Google’s technicians.
Kriti Sharma gave a great Ted Talk on human bias within AI and machine learning. She highlights the issue of a male-saturated digital industry, with the potential for gender bias within the training data.
Joy Buolamwini gave a talk on fighting bias in algorithms, after facial recognition software didn’t recognise her skin tone. The people who coded the algorithm hadn’t taught it to identify a broad range of skin tones and facial structures, highlighting another issue of personal bias.
The technicians at Google could have input their own bias into the training data, by labelling politicians as either positive or negative, or even whole organisations – there is no way to know. If sentiment analysis is a prominent ranking factor within the algorithm, then this may feed into arguments surrounding bias against certain news outlets on Google.
It seems that we have a long way to go before artificial intelligence is trained through unbiased data. Whether this is even possible or not is another topic entirely. For now, we should use sentiment scores as a helpful insight into how machines might understand our content, keeping in mind the potential for bias within the data.
How Marketers Could Use Google’s Natural Language API
- You could compare the salience scores of high-ranking competitor copy to your own copy, see what they are doing well and make improvements. It’s too early to prove that optimising for entity salience can improve rankings, but it will give you an understanding of whether or not Google can understand the topics you’re trying to cover.
- Instead of the old keyword stuffing, you can improve the relevancy of your keywords through their positioning within the text. Follow the salience metrics that Google uses and see whether your content can beat your competitors.
- You could analyse the sentiment behind comments on social media campaigns and create an average to feedback to your campaign manager. Understanding whether feedback was mostly positive or negative could help you to identify areas to improve upon in the next campaign.

